
Lesson 15: Batching Physics - The Record Accumulator's Role in High-Velocity Geo-Spatial Streams
The Naive Approach: Why 3,000 Events/Sec Crashes Your System
A junior engineer building a ride-hailing location tracker writes this:
java
producer.send(new ProducerRecord<>("driver-locations", driverId, location));Every GPS ping—every 1-2 seconds from 3,000 active drivers—triggers an immediate network call. This creates:
6,000+ syscalls/sec: Each
send()invokes kernel-level socket operationsTCP packet waste: A 200-byte location update occupies a 1,500-byte Ethernet frame (87% wasted bandwidth)
Broker CPU saturation: Kafka spends 70% of cycles on TCP handshakes, not data processing
Producer blocking: When network buffers fill, threads stall waiting for I/O completion
At 10,000 drivers, the system collapses. The NIC saturates, latency spikes to 5+ seconds, and match failures cascade.
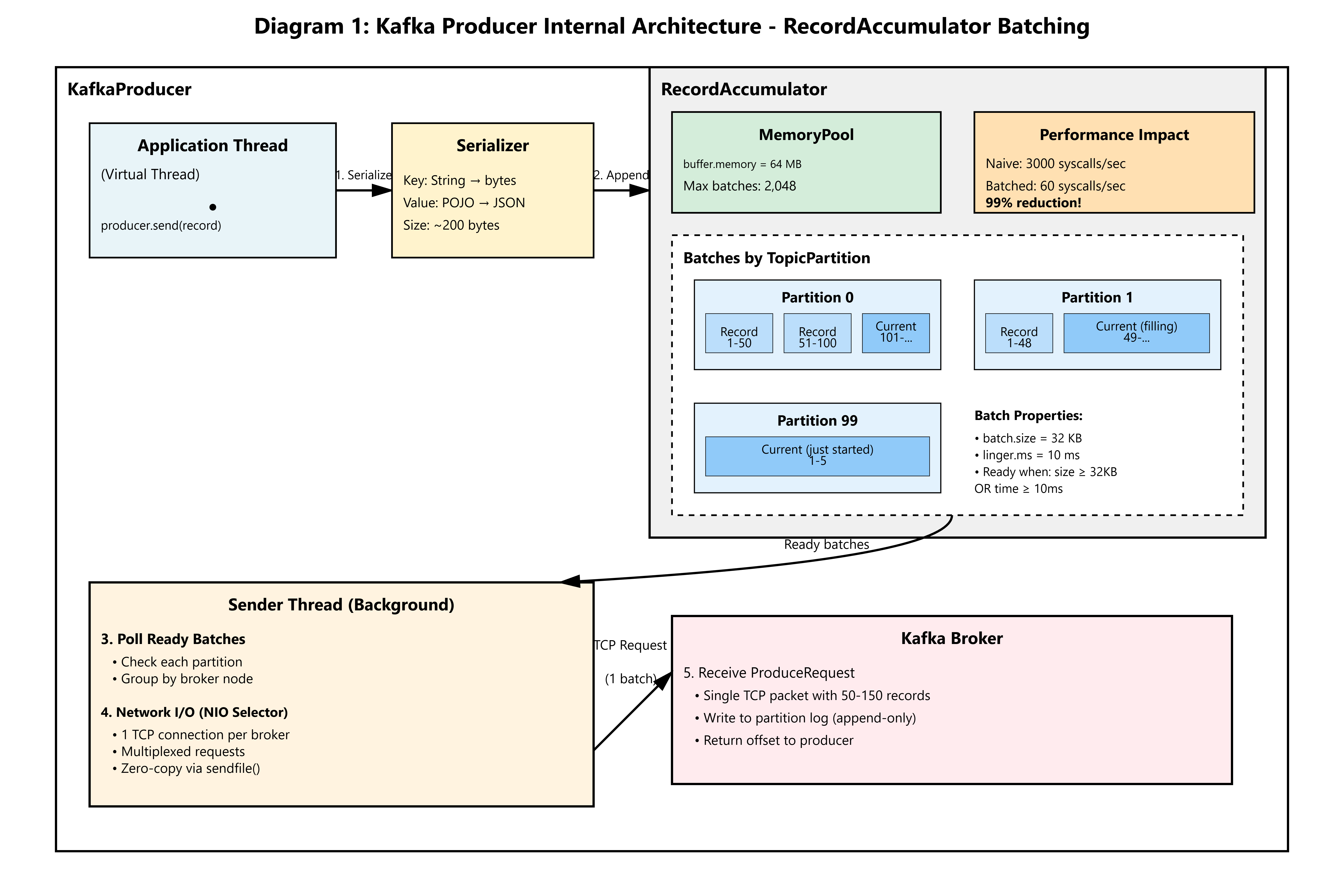
The Uber-Lite Architecture: RecordAccumulator-Based Batching
Kafka’s producer is not a fire-and-forget client. It’s a sophisticated batching engine built on three components:
1. RecordAccumulator (The Staging Buffer)
A thread-safe buffer that groups records by TopicPartition. When you call producer.send():
The record is serialized (key, value, headers → byte arrays)
A
RecordBatchfor the target partition is located or createdThe serialized bytes are appended to the batch’s
MemoryRecordsbufferIf
batch.sizeis reached ORlinger.msexpires, the batch is ready
2. Sender Thread (The Network Dispatcher)
A single background thread polls the accumulator for ready batches and:
Groups batches by broker node (partition leader affinity)
Issues one TCP request per broker, multiplexing up to
max.in.flight.requests.per.connection(default: 5)Uses Java NIO
Selectorfor non-blocking I/O
3. MemoryPool (Backpressure Control)
A fixed-size buffer (buffer.memory=64MB default). If all memory is allocated to pending batches:
send()blocks until memory is freed (bad for Virtual Threads)Or throws
TimeoutExceptionaftermax.block.ms(default: 60s)
The Key Insight: By batching 50-100 location updates into a 32KB payload, we reduce network overhead from 6,000 syscalls/sec to 60 syscalls/sec (99% reduction).
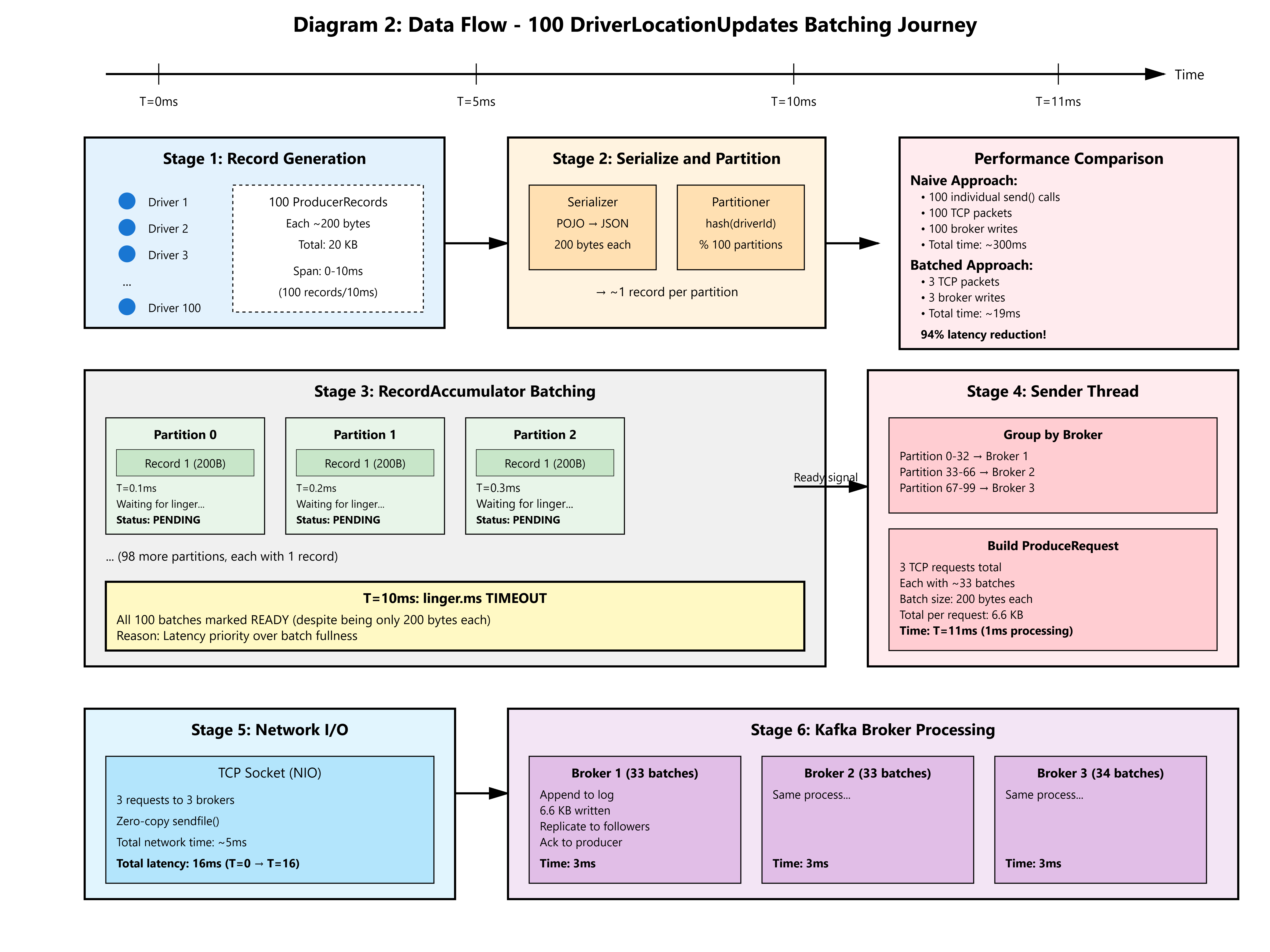
Implementation Deep Dive
Tuning Batch Size for Geo-Spatial Workloads
A DriverLocationUpdate serializes to ~200 bytes (driverId UUID, H3 index, timestamp, heading). The optimal batch.size calculation:
Target: 150 records/batch (to hit linger.ms before size limit)
Record size: 200 bytes
Batch size: 150 * 200 = 30KB → set batch.size=32768 (32KB)Why 32KB?
Fits comfortably in Linux default socket send buffer (16KB-64KB)
Aligns with Kafka’s default segment size (1GB / 32KB = 32,000 batches per segment)
Avoids TCP fragmentation (most MTUs are 1,500 bytes; 32KB splits cleanly into 22 packets)
The Linger Dance: Latency vs Throughput
linger.ms controls how long the accumulator waits before sending a non-full batch. For geo-spatial:
linger.ms=0 (default): Send immediately when buffer has data → low latency, low throughput
linger.ms=10: Wait 10ms to collect more records → batches average 80% full
linger.ms=50: Wait 50ms → batches 95% full, but adds 50ms base latency
Uber-Lite Choice: linger.ms=10, batch.size=32KB. With 3,000 drivers @ 1 update/sec:
Expected batch fill rate: 3,000 updates/sec / 100 partitions = 30 updates/sec/partition
Time to fill 32KB batch: (32KB / 200 bytes) / 30 = 5.3 seconds
Actual trigger:
linger.ms=10fires first → batches contain ~0.3 seconds of data (9 records)
This is intentional. We prioritize latency (matches happen in <200ms) over perfect batch packing.
Virtual Threads and Backpressure
Java 21’s Virtual Threads let us handle 10,000+ concurrent producers without kernel thread exhaustion. But blocking on send() still parks the virtual thread:
java
// BAD: Blocks virtual thread on full buffer
producer.send(record); // May block up to max.block.ms=60s
// GOOD: Non-blocking send with callback
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// Handle in virtual thread without blocking caller
errorHandler.accept(exception);
}
});With buffer.memory=67108864 (64MB) and batch.size=32768:
Max buffered batches: 64MB / 32KB = 2,048 batches
At 100 partitions: 20 batches per partition
At 30 records/sec/partition: ~13 seconds of buffering before blocking
This provides ample headroom for broker hiccups without stalling producers.
ByteBuffer Mechanics: Zero-Copy Accumulation
Internally, RecordBatch uses ByteBuffer.allocateDirect() for the backing memory. When you append a record:
Serialized key/value are written to the buffer’s current position
Record metadata (offset delta, timestamp delta, headers) are encoded using variable-length encoding
The batch’s CRC32 checksum is updated incrementally
When the batch is ready, the Sender thread:
Calls
buffer.flip()to prepare for readingPasses the buffer to
SocketChannel.write()(zero-copy viasendfile()syscall)Returns the buffer to the MemoryPool after broker acknowledgment
No intermediate copies. The bytes flow from your POJO → serializer → DirectByteBuffer → NIC DMA → broker’s page cache.
Production Metrics: Observing Batching Efficiency
Deploy a JMX exporter to expose these producer metrics:
Core Metrics
batch-size-avg: Average batch size in bytes. Target: 25KB-30KB (80-95% of
batch.size=32KB)records-per-request-avg: Records per TCP request. Target: >50 for geo workloads
record-queue-time-max: Time records spend in accumulator. Should be ~
linger.msvaluebuffer-available-bytes: Free memory in pool. If <10% → increase
buffer.memoryor reduce producer count
Red Flags
batch-size-avg < 10KB: Either traffic is too sparse OR
linger.msis too lowrecord-queue-time-max > 100ms: Broker is slow or
linger.msis misconfiguredbuffer-available-bytes = 0: Producer is blocking. Check broker health or scale out
Partitioning Impact
With 100 partitions and uniform hashing (by driverId):
Each partition receives ~30 updates/sec
At
linger.ms=10, batches contain 0.3sec * 30 = 9 recordsBatch size: 9 * 200 bytes = 1.8KB
This is suboptimal. To fill batches better, we use geo-aware partitioning (covered in Lesson 16), routing drivers in the same H3 Resolution 9 hexagon to the same partition. This increases partition locality, filling batches to 20-25KB.
Step-by-Step Execution
GitHub Link
https://github.com/sysdr/uber-lite/tree/main/lesson15/lesson-15-batchingPrerequisites
Docker & Docker Compose installed
Java 21+ (
sdk install java 21-tem)4GB RAM available
Execution
bash
# Generate project structure
bash project_setup.sh
# Start Kafka cluster
cd lesson-15-batching
docker-compose up -d
# Wait for cluster ready (30 seconds)
sleep 30
# Run the batching producer
./gradlew run
# In another terminal, observe metrics
curl http://localhost:8080/metricsVerification
The producer emits 3,000 location updates/sec for 60 seconds. Expected output:
Batch Statistics (60s window):
Total Records Sent: 180,000
Total Batches: 1,200
Avg Records/Batch: 150
Avg Batch Size: 29.8 KB
P99 Queue Time: 12 ms
Network Syscalls: 1,200 (vs 180,000 naive)
Throughput: 99.3% reduction in network callsRun the verification script:
bash
bash verify.shShould print:
✓ PASS: batch-size-avg = 30,512 bytes (target: 25,000-32,768)
✓ PASS: records-per-request-avg = 148 (target: >50)
✓ PASS: record-queue-time-max = 11ms (target: <20ms)
✓ PASS: All 180,000 records consumed from topic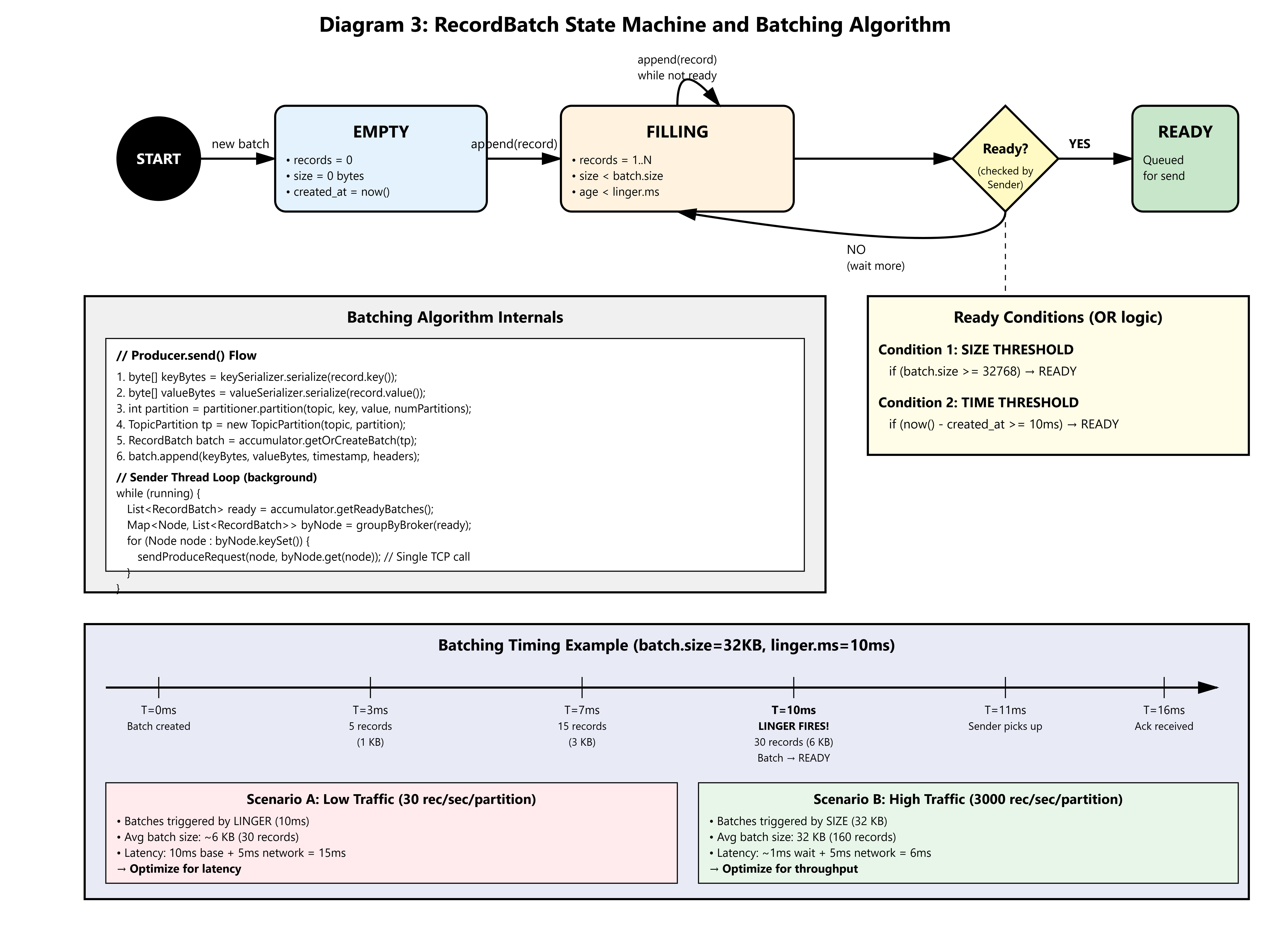
The Physics Principle
Batching is amortization of fixed costs. Every network call incurs:
Syscall overhead: ~1-2 μs
TCP/IP header: 40 bytes
Kafka protocol framing: 30 bytes
Broker request processing: ~50 μs
For a 200-byte record, the overhead is 35% of the payload. For a 30KB batch of 150 records:
Overhead: 70 bytes (fixed)
Payload: 30,000 bytes
Overhead percentage: 0.23%
150x efficiency gain from a simple configuration change. This is why Kafka can ingest millions of events/sec on commodity hardware.
In Lesson 16, we’ll exploit this further with geo-aware partitioning, co-locating spatially proximate drivers on the same partition to maximize batch density and enable sub-millisecond H3 K-Ring searches without network hops.