
Lesson 29: Implementing the H3-Based Custom Kafka Partitioner
The Problem: Why DefaultPartitioner Destroys Geo-Spatial Joins
When a junior engineer wires up a ride-sharing event pipeline, they serialize the driver ID as the Kafka record key and let DefaultPartitioner do its thing:
// The naive approach — don't do this
producer.send(new ProducerRecord<>("driver-locations", driverId, locationEvent));
DefaultPartitionerruns murmur2 over the UTF-8 bytes of"driver-uuid-abc123". The result is geographically random. Driver A in downtown SF lands on partition 17. Driver B, 40 meters away, lands on partition 43. Rider C, requesting a pickup between them, lands on partition 2.
When your Kafka Streams topology tries to join
driver-locationswithrider-requests, the framework detects the partition mismatch and emits a repartition topic:driver-locations-KSTREAM-JOINED-repartition. Every record now makes two network hops through the broker instead of one. At 3,000 events/sec, that repartition topic absorbs ~40MB/min of redundant traffic. YourStreamThreadpoll loop starts missing itsmax.poll.interval.msdeadline. Consumer group rebalances cascade. The on-call engineer gets paged.
The root cause: your partition assignment function has no geographic awareness. The fix: replace it with one that does.
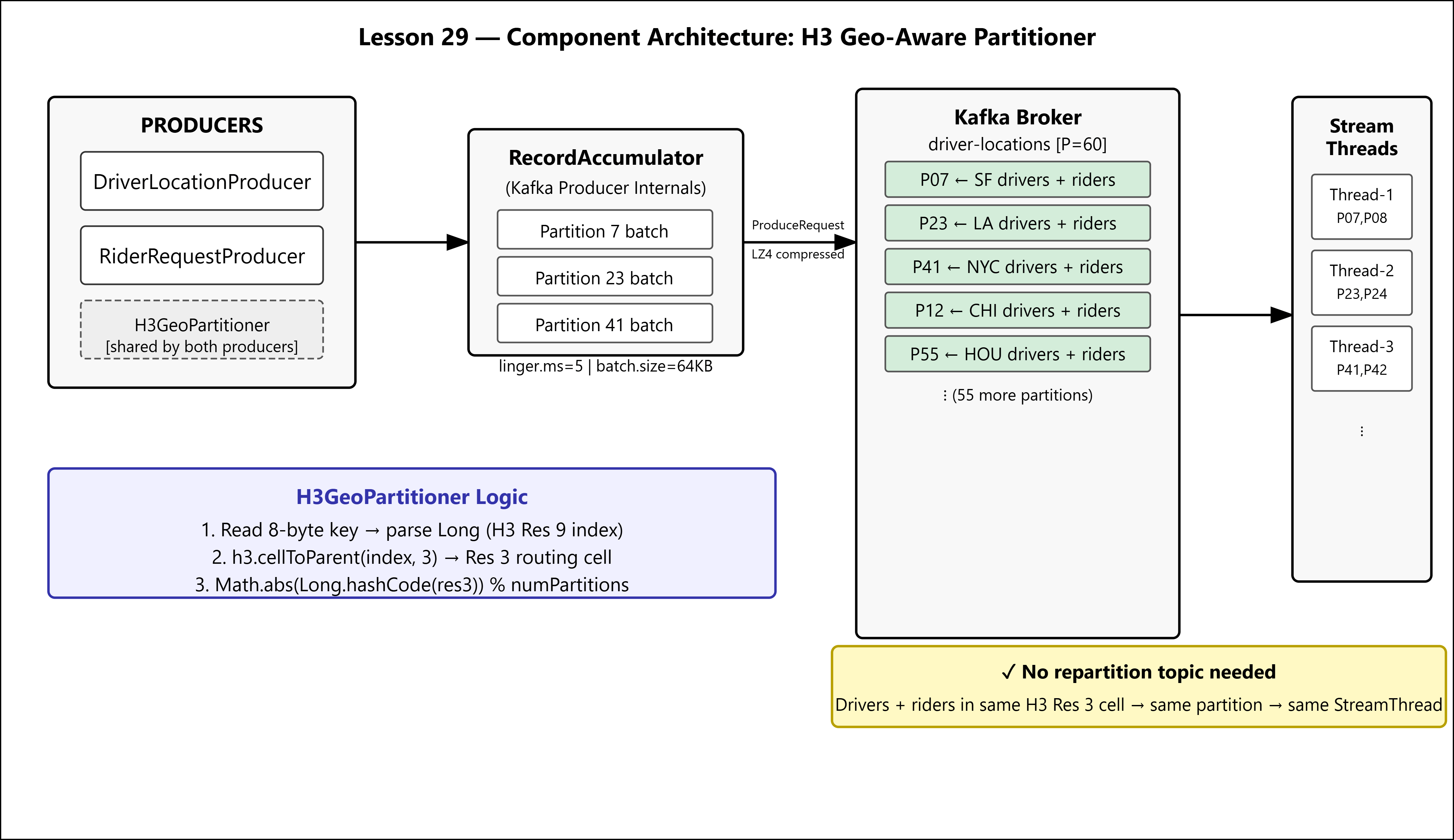
The Uber-Lite Architecture: H3 Res 3 as a Routing Contract
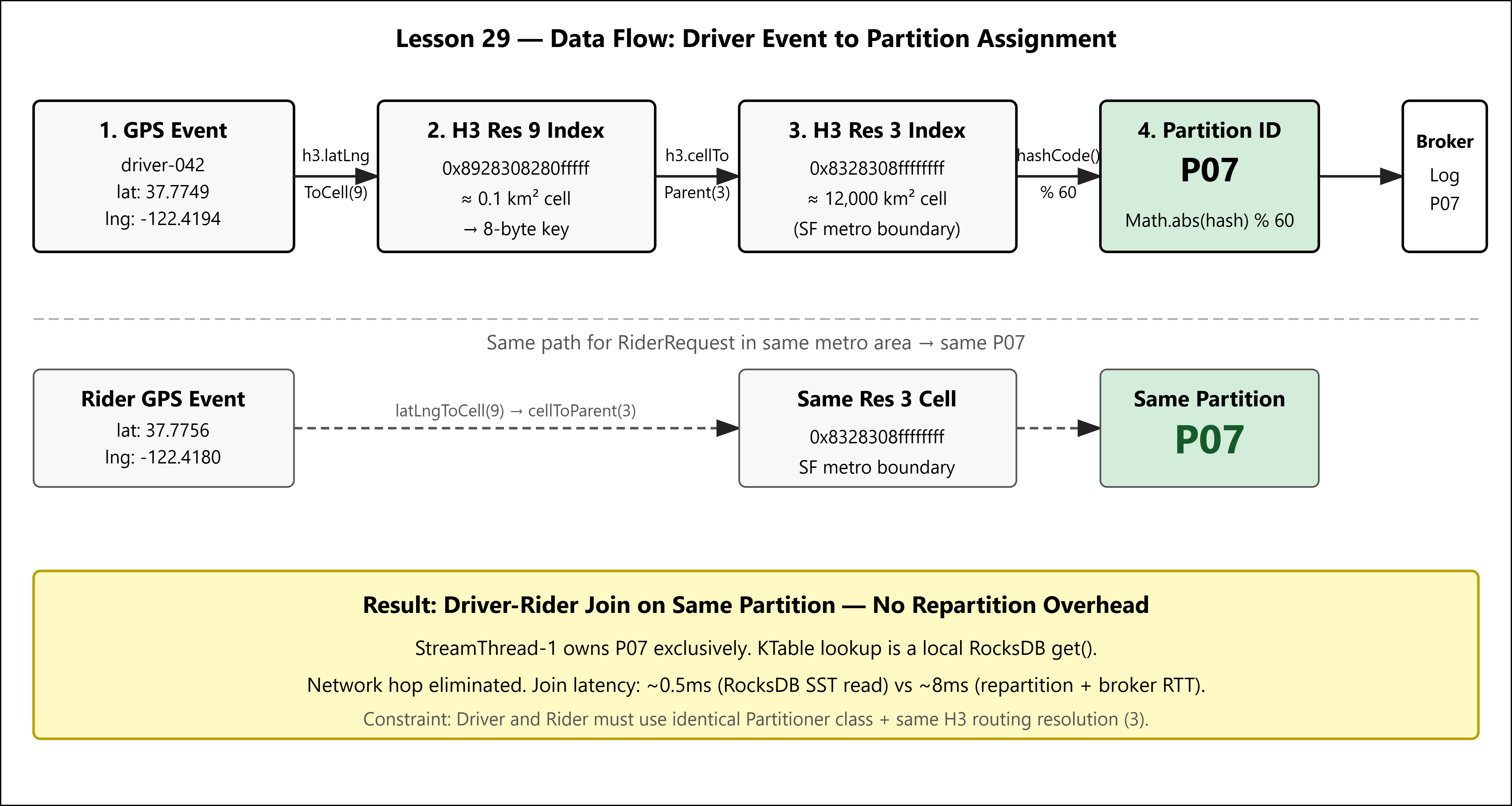
H3 Resolution 3 hexagons cover approximately 12,000 km² each — the footprint of a major metropolitan area. The continental US fits into roughly 90 Res 3 cells. With a 60-partition topic, multiple Res 3 cells map to each partition, but the critical property holds: drivers and riders within the same Res 3 cell always hash to the same partition.
The routing contract:
partition_id = Math.abs(h3.geoToH3(lat, lng, 3).hashCode()) % NUM_PARTITIONS
Both the driver location producer and the rider request producer use the same partitioner class with the same resolution. The Kafka broker sees records with the same key hash arriving at the same partition. The StreamThread processing that partition does the join entirely in local memory — no repartition topic, no network hop.
This is data locality by construction. You’re not hoping the framework will optimize it; you’re enforcing it at the partition assignment layer.
Implementation Deep Dive
The Three Failure Modes to Avoid
Failure 1: Negative partition IDs. Java’s Long.hashCode() is (int)(value ^ (value >>> 32)). For large H3 index values, this frequently produces negative integers. n % 60 on a negative n in Java returns a negative remainder (Java’s % is remainder, not modulo). Kafka’s broker rejects negative partition IDs with InvalidPartitionException. The producer retries, hits max.block.ms, and blocks your application thread.
Fix: Math.abs(h3Index.hashCode()) % numPartitions.
Failure 2: Hardcoded partition count. The Partitioner interface receives the live cluster metadata at partition() call time via the cluster parameter. Never hardcode numPartitions. In CI, topics have 3 partitions. In staging, 30. In production, 60. Your partitioner must read cluster.partitionCountForTopic(topic).
Failure 3: String serialization of H3 indices. H3 indices are 64-bit longs. Stringifying them ("612986237100498943") wastes 18 bytes on the wire and forces a String parse on every hashCode call. Serialize them as raw 8-byte ByteBuffer arrays. The partition key bytes are what Kafka’s internal RecordAccumulator uses to route records to the batch for the correct partition — keep them compact and deterministic.
The Partitioner Class
public final class H3GeoPartitioner implements Partitioner {
private static final H3Core h3;
static {
try { h3 = H3Core.newInstance(); }
catch (IOException e) { throw new ExceptionInInitializerError(e); }
}
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
int numPartitions = cluster.partitionCountForTopic(topic);
long h3Index;
if (key instanceof Long l) {
// Key is already a pre-computed H3 Res 3 index
h3Index = l;
} else if (keyBytes != null && keyBytes.length == 8) {
h3Index = ByteBuffer.wrap(keyBytes).getLong();
} else {
// Fallback: re-hash uniformly to avoid partition starvation
return Utils.toPositive(Utils.murmur2(valueBytes)) % numPartitions;
}
return Math.abs(Long.hashCode(h3Index)) % numPartitions;
}
}
Producer Configuration
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, H3GeoPartitioner.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getName());
// Batch aggressively — geo events cluster in space and time
props.put(ProducerConfig.LINGER_MS_CONFIG, "5");
props.put(ProducerConfig.BATCH_SIZE_CONFIG, "65536"); // 64KB
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4");
LINGER_MS=5 means the RecordAccumulator holds records for 5ms before flushing. During a surge (rush hour, rain event), drivers in the same hex send updates within the same 5ms window. They batch together in the accumulator, get compressed as a unit, and land on the broker in a single ProduceRequest. LZ4 achieves 3:1 compression on repetitive lat/lon JSON. Your broker CPU stays sane.

Key Serialization Contract
Both producers (driver and rider) must serialize the H3 index identically:
public static byte[] h3ToBytes(long h3Index) {
return ByteBuffer.allocate(Long.BYTES).putLong(h3Index).array();
}
// At the call site:
long cell = h3.geoToH3(driver.lat(), driver.lng(), 3); // Resolution 3
producer.send(new ProducerRecord<>(TOPIC, h3ToBytes(cell), eventBytes));
Resolution 3 is the routing resolution. Internally, your RocksDB state store indexes at Resolution 9 (average area ~0.1 km²) for precision matching. The partition key (Res 3) is the coarse routing contract; the state key (Res 9) is the fine-grained lookup key. Never conflate the two.
Production Metrics
Watch these in your JMX/Grafana dashboard:
MetricThresholdMeaningkafka.producer:type=producer-metrics,name=record-error-rate0Non-zero = InvalidPartitionException in your partitionerkafka.consumer:name=records-lag-max per partition<500Partition skew — one partition overwhelmedkafka.streams:name=process-latency-max<50msStreamThread falling behind on joinkafka.producer:name=batch-size-avg>16KBConfirms batching is workingPartition distribution CV<0.05Coefficient of variation of message counts across partitions
To detect partition skew: consume the
driver-locationstopic for 60 seconds, count messages per partition, computestddev(counts) / mean(counts). Target CV < 5%. H3 Res 3 cells are uniform-area hexagons by construction, so skew should be driven purely by real population density differentials, not by hash distribution artifacts.
Step-by-Step Execution
GitHub Link
https://github.com/sysdr/uber-lite/tree/main/lesson29/lesson-29-h3-partitioner
Prerequisites
Docker 24+ with Compose V2
Java 21+
Maven 3.9+
Run
chmod +x project_setup.sh && ./project_setup.sh
cd lesson-29-h3-partitioner
mvn clean package -q
docker compose up -d
# Wait for Kafka to be ready (~10s)
mvn exec:java -Dexec.mainClass="com.uberlite.lesson29.PartitionerDemo"
Verify
chmod +x verify.sh && ./verify.sh
The verification script sends 6,000 driver location events (100 drivers × 60 updates) across 6 H3 Res 3 cells, then measures partition distribution. It prints PASS: partition skew CV=X.XX% if CV < 5%, otherwise FAIL.