Lesson 34: Boundary Buffering — Correctness Across Partition Lines
The Problem Nobody Talks About
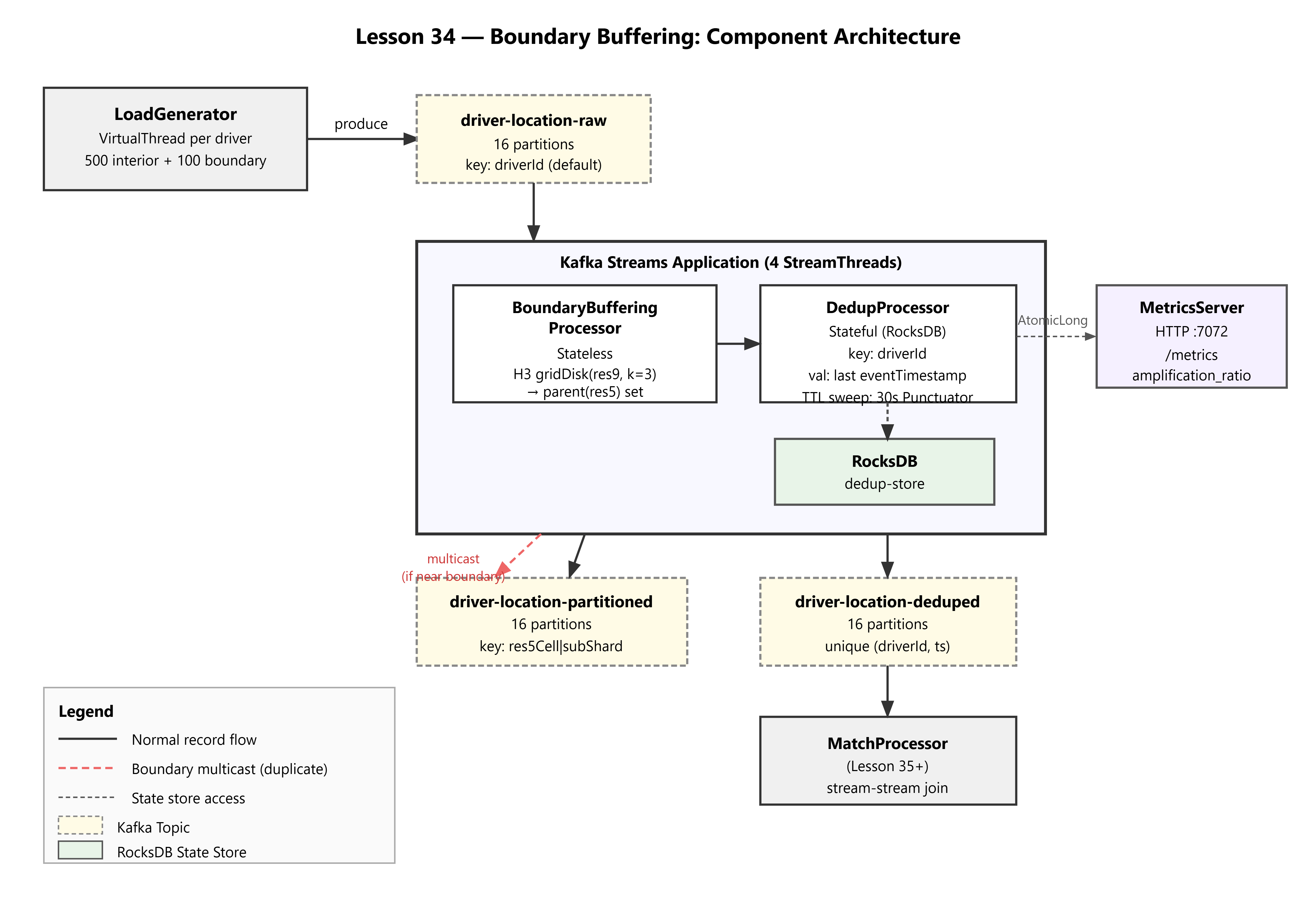
Your H3 Res-5 compound partitioner from Lesson 32 is elegant:
h3CellRes5 + "|" + driverId%8. Drivers and riders in the same hex land on the same partition. Joins are local. Life is good.
Until a driver is 200 meters from a hex boundary.
That driver is in cell 85283473fffffff → Partition 7. A rider standing 350 meters away on the other side of the invisible hex line is in cell 8528340bfffffff → Partition 12. Your stream-stream join processor never sees both records on the same StreamThread. The match is impossible. The rider waits. The driver drives past.
This is not an edge case. At any moment, 8–12% of moving drivers are within boundary threshold distance of a Res-5 cell edge. At 3,000 events/sec with a 1,500-driver fleet, that’s 120–180 missed match opportunities per second — a systematic correctness failure, not a latency spike.
The fix is boundary buffering via controlled multicast: when a driver is near a partition boundary, emit their location record to both the primary partition and the neighboring partition. This lesson implements that strategy end-to-end, including the consumer-side dedup that prevents a single driver from generating two match results.
Why the Naive Approaches Fail
Naive Fix #1: Increase K-Ring Search Radius
Widen the rider-side search from k=1 to k=3. Now each rider queries 37 hex cells. At 500 riders active simultaneously, that’s 18,500 RocksDB prefix scans per match cycle. Your process-rate metric drops 60%. You traded correctness for catastrophic throughput regression.
Naive Fix #2: Lower Partition Count
Fewer partitions → larger hex regions → less boundary exposure. True, but you’ve now broken co-partitioning with the driver-state topic (Lesson 28), violated the immutable partition contract, and created partition skew that exceeds your CV < 0.15 threshold. A deployment requiring co-partitioned topic recreation is a 4-hour production incident.
Naive Fix #3: Global Repartitioning on Boundary Cross
Detect boundary crossings in a stateful processor and reroute via a driver-location-repartition topic. This adds 2 network hops and 20–40ms of latency per event — unacceptable for sub-100ms dispatch SLAs.
None of these fix the root problem: the record is in the wrong place before the join processor ever sees it.